 云端操控万千数据
云端操控万千数据

 云端操控万千数据
云端操控万千数据
HTML语言、数据类型和运算符、流程控制、数组
HTML基础标签
表单标签&框架标签&新增标签
CSS常见选择器&CSS样式
CSS盒子模型&CSS3新增属性
12306网站
使用HTML和CSS技能,完成新版12306网站首页的开发。主要涉及HTML的div、span、form、a、img、ul、dl、等标签的使用,涉及CSS选择器、常用属性、定位、浮动、盒子模型等的使用。
课程三维度全方位定制8.0

课程内容技术涵
盖全面深入浅出

课程实操案例多
扩展思路举一反三

与当下企业项目保
持一致技术架构
课程体系全新升级 稳居前沿风向标
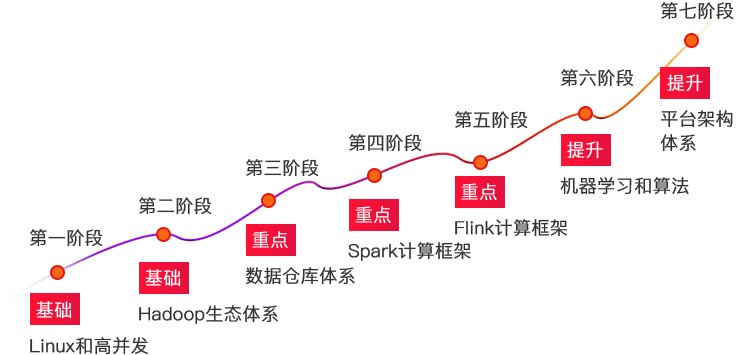
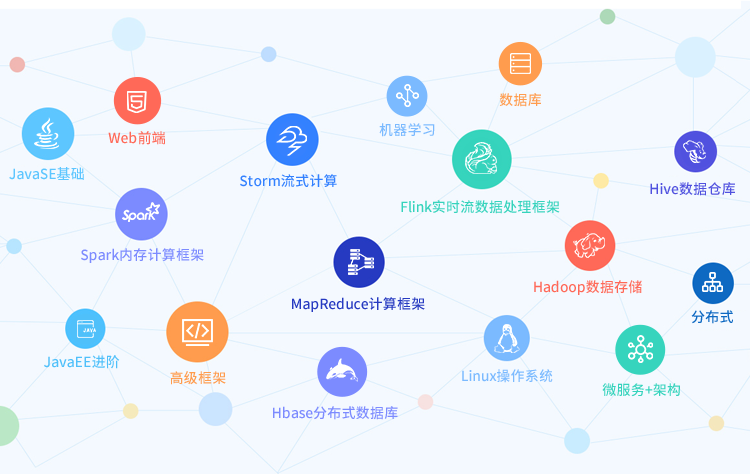
大数据课程依据学员基础分为三大班级,基础班、就业班、高手班课程整体贯穿项目,以项目为依托。
多行业大型实战项目

基于热门行业领域联合研发部,共同研发“大厂级”深度项目

项目实战占比超40%涵盖电商,金融,教育等行业

大厂级企业真实项目不做dem o,紧贴市场

身处真实企业环境,为进入企业提前准备

中国银行审计
数据集市平台

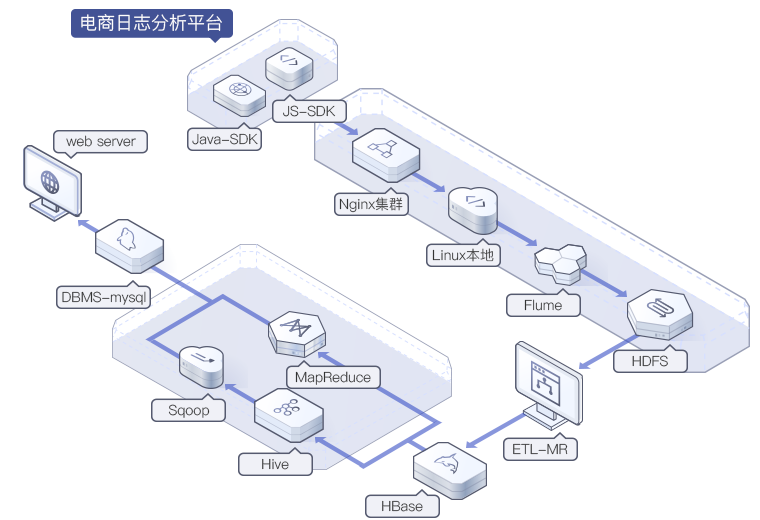
电商日志分析
数据挖掘项目

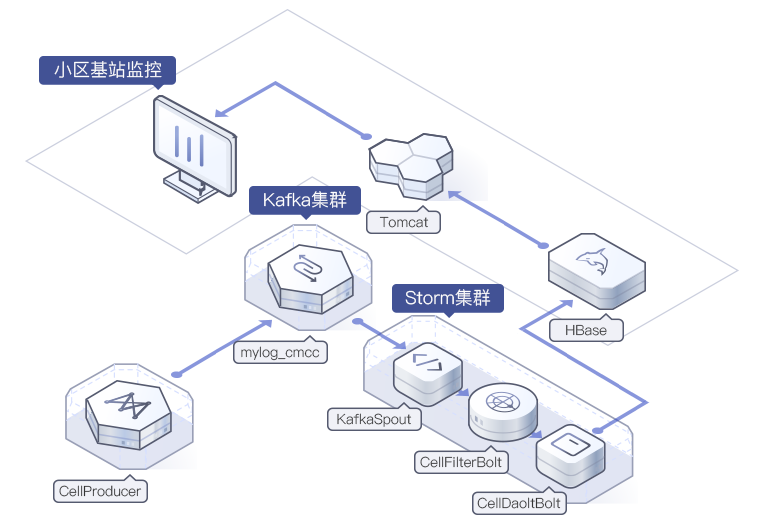
电信CMCC基站
掉话率分析系统
酷狗音乐数据
中心平台
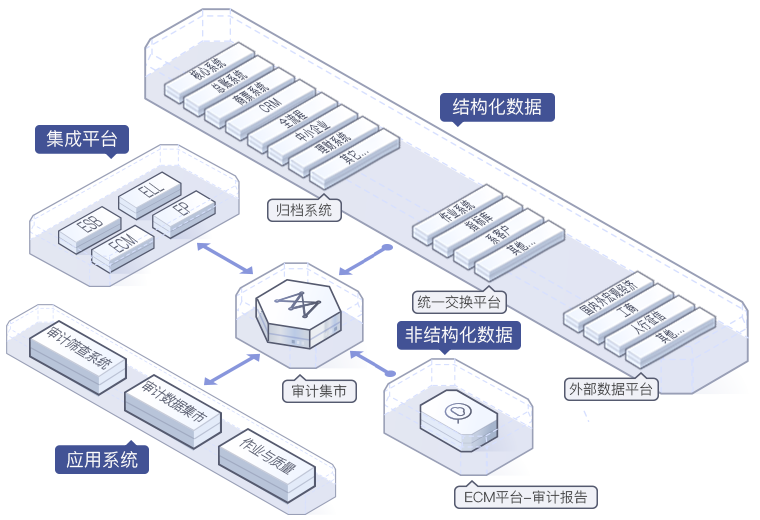
中国银行审计数据集市平台项目是一个集在线大数据分析、疑点扫描、风险评估、事件预警、跟踪预警、线索聚集、数据表级操作为一体的通用平台。其中主要内容包含数据仓库的建设,数据集市建设,数据流转分析等功能。本项目可以让我们学习到真正的大数据公司如何对数据仓库及数据集市平台进行设计和搭建,如何对数据进行模型化分析,此项目基于同学们掌握的大数据基础知识进行实战化训练,强化同学们对数据模型的建立。
多行业大型实战项目
尚学堂的四大优势给你选择我们理由
掌握 Linux 必备知识,慢慢深入结合实战开始学习 Hadoop、HBase、Hive,Flink、 Spark 等应用层面
课程根据市场需求和国内一线企业刚需紧密结合,涵盖大数据领域各个技术点,以合格的阿里 P6 大数据开发工程师为培养目标,增加主流技术,确保竞争优势
不论学习或是工作中遇到问题难点,你的背后是尚学堂大数据专家的教学技术团队,顺利通关面试和实习环节
课程的设计和内容都是来自国内一线大厂的讲师,真正做到项目技术难点紧密结合,学习大咖思维,跟名师,成为大数据开发工程师
 软硬实力并驾齐驱“从薪开始”
软硬实力并驾齐驱“从薪开始”
注重与企业、招聘平台密切合作,联合共建、定向输出优质人才
剖析实用技术、洞悉行业趋势,实现学员与岗位无缝对接













 基础能学吗?
基础能学吗?